Coronavirus disease (COVID-19) has become an important public issue across the globe since December 2019. As of 12th of April 2020, more than 1.79 million cases have been reported in 210 countries and territories (Worldometer, 2020). It affects people worldwide and there is no vaccine yet for this virus. Certain types of pneumonia are implicated to the new coronavirus, which is considered a big threat to global public health. There is an urgent need to develop potent anti-COVID-19 agents for the prevention of the outbreak and stop viral infections.
E4C aim
E4C aims at leveraging EU’s supercomputing resources coupling them with some of the continent’s best life-science research labs to counter international pandemics faster and more efficiently. At the core of the project is EXSCALATE (EXaSCale smArt pLatform Against paThogEns), at present the most powerful (and cost-efficient) intelligent supercomputing platform in the world, developed by Dompé Farmaceutici SpA. EXSCALATE leverages a "chemical library" of 500 billion molecules, thanks to a processing capacity of more than 3 million molecules per second.
CADD and High throughput biochemical and phenotypic screening
Advanced CADD, in combination with the high throughput biochemical and phenotypic screening, will allow the rapid evaluation of the simulation results and the reduction of time for the discovery of new drugs.
This approach is especially useful against pandemic viruses and other pathogens, where the immediate identification of effective treatments is of paramount importance.
High throughput biochemical and phenotypic screening enables scientists to test thousands of samples simultaneously. Using automation, the effects of thousands of compounds can be evaluated on cultured cells, or using biochemical in vitro assays. The goal of HTS is to be able to identify or “hit” compounds that match certain properties. As HTS is usually conducted on very large libraries of compounds the volume of raw data that is produced is usually huge. This calls for an analysis tool that is able to handle large volumes of data easily and most powerful computing resources available.
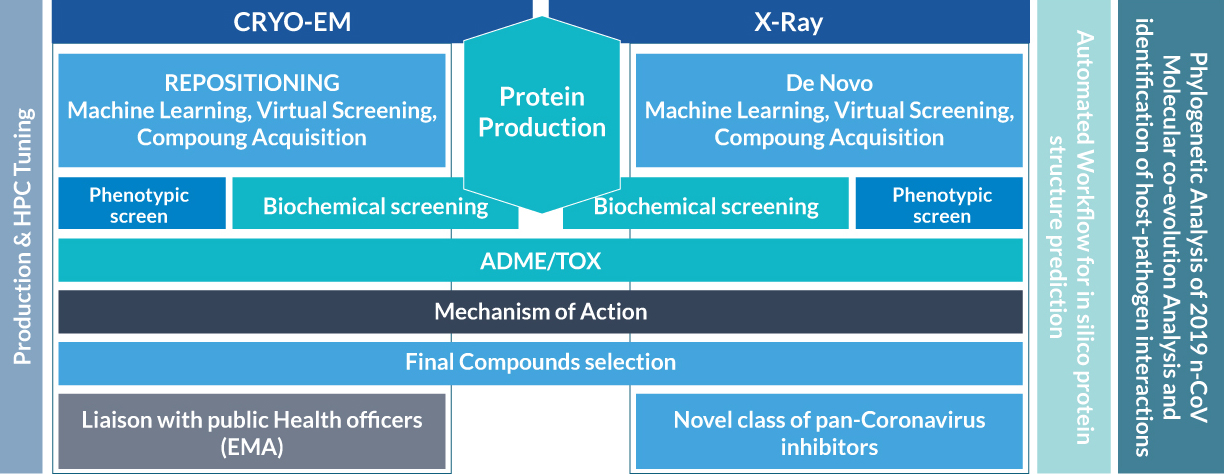
The Workflow
Through the EXSCALATE platform and the virtual screening protocols, E4C selects
1.
the most promising drugs against coronavirus taken from the commercialized and developing drugs safe for humans (> 10000 drugs, SIM);
2.
and screen the proprietary Tangible Chemical Database (TCDb), comprising > 500 billion molecules to identify new potential drugs to be tested against coronavirus, thus enhancing the success rate of the virtual screening step.
The aim of E4C is twofold: to identify molecules capable of targeting the coronavirus (2019-nCoV) and to develop an effective tool for countering future pandemics to be consolidated over time.
1. Establish a sustainable example for a fast scientific answer to any future pandemic scenario
2. Accomplish point 1 by: establishing a rapid and effective HPC platform for the generation and analysis of 3D models and experimental 3D structure resolution (X-Ray and/or Cryo-EM) of protein targets from pandemic pathogens
3. Within the above platform, drive a fast virtual identification of known drugs (repurposing) or proprietary/commercial candidate molecules to be further experimentally characterized
4. Define a workflow scheme for biochemical and cellular screening test to validate the candidate molecules in previous points and assure, through phenotypic and genomic assays, the identification of further possible Mechanism of Action (MoA), not exploited in points 2 and 3.
5. Recycle new identified MoAs to point 2
6. Prepare together with EMA a development plan for successful candidates for direct “first in human” kind of studies or for further testing in animals for bridging studies.
7. Identify COVID-19 genomic regions involved in host adaptation and pathogenicity
8. Identify co-evolving protein interfaces involved in host-pathogen interactions
Basically, there will be two highly interconnected workstreams of scientific activities that will be executed. One will be primarily computerized and will involve several bioinformatic and chemoinformatic technologies and algorithms, while the second, complementary and deeply interconnected with the first, will be more focused on experimentally informed genomic, biochemical and biological steps.
Starting from known bioinformatic information of the protein targets a CADD activity (WP1) will be performed to generate the starting point for the virtual screening methodology (EXSCALATE) and downstream activities foreseen in WP7 and WP8. In parallel, within WP2 protein cloning, expression and purification will immediately start to produce enough bioorganic material to support experimental testing within biochemical assays (WP2 and WP6), phenotypic and cellular assays (WP3, WP5 and WP6) and structural biology effort (WP4).
E4C Drug Discovery Workflow
This scheme shows Work Packages (WP) structure and a time dimension of the project activities in a top-down manner.
The massive virtual screening activities need a huge computational resource, therefore the activities will be supported and empowered by four of the most powerful computer centers in Europe namely HPC5 (Eni), MARCONI-100 (CINECA), Barcelona Supercomputing Center and FZ Jülich. These Tier-0 supercomputing centers are able to jointly guarantee the best combination of hardware architectures, required knowledge and the highest speed-up for the simulations.
In addition, INFN (CERN Tier-1 center) makes their data sharing and high throughput infrastructure available to facilitate product exploitation.
The considerable amount of sequence information coming from all scientific communities and hospitals will be surely captured by consolidated pipelines of several public databases.
EXSCALATE
EXSCALATE a Ultra High Performance Virtual Screening Platform for computer aided drug design (CADD), based on LiGen, an exascale software able to screen billion of compounds in a very short time, and a library of trillion of compounds.
Ligen
The most relevant tool of EXSCALATE is the de novo structure based virtual screening software LiGenTM (Ligand Generator), designed and developed to run on High Performance Computing (HPC) architectures.
In the ANTAREX framework, a LiGenTM implementation, ready for exascale HPC application was obtained, capable of running at 1,000 or more petaflops.
In more detail LiGenTM is a suite of programs able to define flexible de novo design workflows by using both pharmacophores and molecular docking engines, linking the fragments in situ, and directly scoring the drug likeness of the generated molecules. LiGen consists of a set of tools which can be combined in a user- defined manner to generate project centric workflows. Alternatively, the modules can be used as a standalone service according to the user’s need.
EXSCALATE platform on new Tier-0 HPC systems
The E4C project leverages the experience of ANTAREX and the separation of concern approach used in the design of LiGen to adapt relevant modules to new Tier-0 systems including heterogeneous architectures (one of the most relevant and time consuming kernels, GEODOCK has already been ported to GPU). The adaptation may then include numerical kernel optimizations (e.g. vectorization) and the use of directive based programming paradigms, such as OpenMP or OpenACC, and where performances will be dictated by the critical use of CUDA kernels (for NVIDIA GPU accelerated systems).
Besides the few time consuming kernels to be adapted to exploit hardware acceleration (e.g. porting to GPUs or vector processors), the computation is limited to flow control code and I/O to tune it for the specific file system of the target Tier-0 HPC system.
Address
Exscalate4cov
c/o Dompé Farmaceutici
Via Tommaso De Amicis, 95
80145 Napoli, Italy