● UPDATED
● UPDATED











The information you provide will be used as input
into our High Performance Computing resources for
virtual screening against priority target
protein structures.
As part of its dissemination plan, E4C consortium is
making a repository available here for publications
originating from the project's activities following green
open access principles.

CADD

PROTEIN PRODUCTION AND TARGET BASED ASSAYS

PHENOTYPIC SCREEN
STRUCTURAL BIOLOGY

GENOMICS

MECHANISM OF ACTION

AUTOMATED HOMOLOGY MODELING WORKFLOW FOR DRUG TARGET
PRODUCTION AND TUNING ON HPC INFRASTRUCTURE

REGULATORY CONTRACTS
DISSEMINATION & EXPLOITATION OF THE FOREGROUND
Summary
Generation of homology models based on the mapped functional proteins of the entire sequenced SARS-CoV-2 viral genome
Summary
Identification of inhibitors of SARS-CoV-2 3CL-Pro enzymatic activity using a repurposing screen (“target confirmation of main protease”)
Summary
The structural biology team of Elettra Sincrotrone Trieste has focused on SARS-CoV-2 Mpro viral protein by setting up a reproducible expression, purification and crystallization protocol and using thermal stability profiling to define protein quality control and batch to batch reproducibility.
Summary
Main activities performed in WP5 include the use of techniques for molecular evolution, phylogenetic and multiple correspondence analysis (MCA) for the identification of genomic and protein sites associated with SARS-CoV-2 adaptation and host-pathogen interaction.
Summary
n the WP8 “Production and tuning on HPC infrastructure”, the POLIMI team is responsible for the continuous tuning and code adaptation of the EXSCALATE platform, and contributes to its porting on the new Marconi100 partition at CINECA.
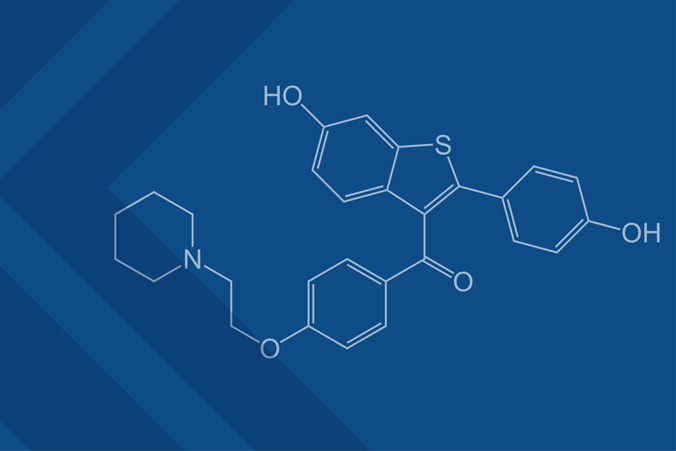
Raloxifene
Raloxifene has emerged from the Exscalate platform as a molecule with potential effectiveness against SARS-CoV-2, based on antiviral targeting.
Exscalate4cov
c/o Dompé Farmaceutici
Via Tommaso De Amicis, 95
80145 Napoli, Italy



















| This project is supported by the European Union’s Horizon 2020 research and innovation programme under grant agreement No 101003551. |
|
© Copyright 2021 - All Rights Reserved |